Interprestasi Analisis Cluster Non Hirarki dengan SPSS
Setelah kita berhasil melakukan proses Analisis Cluster Non Hirarki dengan SPSS, maka langkah selanjutnya adalah menginterprestasikan hasilnya. Mari kita bersama-sama pelajari tutorial interprestasi analisis cluster non hirarki dengan SPSS. Langsung saja anda buka output view anda yang sudah anda hasilkan dari artikel sebelumnya.

Initial Cluster

Tabel “Initial Cluster Centers” di atas merupakan tampilan awal proses clustering sebelum dilakukan proses iterasi.
Iterasi Analisis Cluster
Agar kita dapat mengetahui berapa kali dilakukan proses iterasi yang dilakukan pada objek sebanyak 14 sampel, dapat anda lihat di bawah ini:

Dari tabel “Iteration History” di atas, dapat diketahui bahwasanya proses iterasi dilakukan sebanyak 3 kali. Proses ini dilakukan untuk mendapatkan cluster yang tepat. Dapat diketahui bahwa jarak minimum antar pusat cluster yang terjadi dari hasil iterasi adalah 3,632.
Output Analisis Cluster dengan SPSS
Hasil akhir dari proses clustering dapat anda lihat seperti di bawah ini:


Pada output di tabel “Final Cluster Centers” dapat anda perhatikan, bahwasanya data di atas masih terkait dengan proses standarisasi yang mengacu pada z-score dengan ketentuan sebagai berikut:
- Nilai negatif (-) berarti data berada di bawah rata-rata total
- Nilai positif (+) berarti data berada di atas rata-rata total.
Rumus Cluster
Rumus yang digunakan sebagai berikut:

Di mana:
X = Rata-rata sampel dalam cluster
μ = Rata-rata populasi

Z = Nilai standardisasi
σ = Standar Deviasi
Misalnya, apabila ingin mengetahui rata-rata nilai Geografi dalam cluster 1, yaitu:
(rata-rata nilai Geografi seluruh siswa) + (0,06984 x Standar Deviasi rata-rata Nilai Geografi)
= 69,43 + (0,06984 x 13,91)

= 70,4015
Jadi rata-rata nilai geografi yang berada pada cluster 1 adalah 70,4015.
Demikian seterusnya dapat diketahui rata-rata nilai masing-masing variabel dalam tiap cluster.
Interprestasi Analisis Cluster Non Hirarki dengan SPSS
Interprestasi Analisis Cluster Non Hirarki dengan SPSS adalah: Berdasarkan tabel “Output Final Cluster Centers”, dengan ketentuan yang telah dijelaskan di atas, dapat didefinisikan sebagai berikut:
Cluster 1:

Dalam cluster 1 ini berisi siswa dengan nilai ekonomi dan sosiologi yang rendah, nilai geografi yang sedang serta nilai anthropologi dan tata negara yang tinggi.
Cluster 2
Dalam cluster 2 ini berisi siswa dengan nilai ekonomi dan sosiologi yang rendah, nilai anthropologi dan tata negara yang sedang serta nilai geografi yang tinggi.
Cluster 3
Dalam cluster 3 ini berisi siswa dengan nilai ekonomi, anthropologi, geografi dan tata negara yang rendah serta nilai sosiologi yang sedang.

Perlu diingat kembali, penamaan masing-masing cluster sangat bersifat subjektif tergantung pada peneliti dengan mengacu pada tujuan penelitian.
Tahapan selanjutnya yang perlu dilakukan yaitu melihat perbedaan variabel pada cluster yang terbentuk. Dalam hal ini dapat dilihat dari nilai F dan nilai probabilitas (sig) masing-masing variabel, seperti yang dapat anda lihat dalam tabel berikut:

Rumus ANOVA
Sedikit review, bahwa rumus dari uji F Anova adalah:

Dimana dalam tabel ANOVA di atas “MS Between” ditunjukkan oleh nilai “Means Square” dalam kolom “Cluster”, sedangkan “MS Within” ditunjukkan oleh nilai “Means Square” dalam kolom “Error”.
Kesimpulannya adalah:

Semakin besar nilai F dan (sig < 0,05), maka semakin besar perbedaan variabel pada cluster yang terbentuk.
Kesimpulan Analisis Cluster
Maka berdasarkan tabel yang kita dapatkan dalam tutorial ini, yaitu bahwa untuk instrumen “Tata Negara” adalah variabel yang paling menunjukkan adanya perbedaan diantara siswa-siswa pada ketiga cluster yang terbentuk. Hal ini dengan ditunjukkannya nilai F = 27,528 dan sig = 0,000. Dan untuk variabel yang lain dapat anda didefinisikan lebih lanjut.
Langkah selanjutnya adalah untuk mengetahui jumlah anggota masing-masing cluster yang terbentuk, yaitu dengan melihat pada tabel output di bawah ini:

Pembagian Cluster
Nampak jelas bahwa cluster-1 beranggotakan 5 siswa, cluster-2 berisi 5 siswa, dan pada cluster-3 terdapat 4 siswa yang mengelompok. Dan untuk mengetahui siswa-siswa mana saja yang masuk dalam kategori tiap-tiap cluster dapat kembali dibuka tampilan “data view” dari dataset SPSS anda, yaitu pada kolom terakhir akan nampak seperti berikut ini:

Perhatikan 2 kolom terakhir pada tabel di atas. “qcl_1” menunjukkan nomor cluster dari keberadaan siswa, dan “qcl_2” merupakan jarak antara obyek dengan pusat cluster. Dengan demikian, dapat ditafsirkan sebagai berikut:
Cluster-1 : berisikan Siswa A, C, E, F, dan I dengan masing-masing jarak terhadap pusat cluster-1 adalah 0,82973; 1,58817; 1,83593; 0,25547; dan 1,54385.
Cluster-2 : berisikan siswa B, G, J, L dan N, dengan masing-masing jarak terhadap pusat cluster-2 seperti yang anda lihat pada kolom “QCL_2”.
Cluster-3 : berisikan Siswa D, H, K, dan M, dengan masing-masing jarak terhadap pusat cluster-3 seperti yang anda lihat pada kolom “QCL_2”.
NB: Apabila pada Analisis Cluster Hirarki dengan SPSS, pemberian tanda sampel menjadi anggota cluster mana, dapat dilihat pada “Output View” dan “Dataset”, tetapi pada Analisis Cluster Non Hirarki dengan SPSS, tanda itu hanya dapat dilihat pada “Dataset” saja.
Demikianlah semua materi yang berkaitan dengan Analisis Cluster. Semoga artikel Interprestasi Analisis Cluster Non Hirarki dengan SPSS ini dapat bermanfaat bagi para peneliti atau mahasiswa yang sedang membaca jurnal tutorial ini.
By Anwar Hidayat


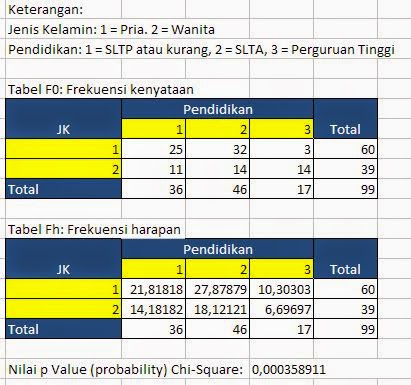



trima kasih banyak, tulisannya sangat membantu….
alhamdulillah terimakasih
Sama-sama