Tutorial ARIMA dengan EViews: Penjelasan dan Panduan Lengkap
Dalam kesempatan ini kita akan membahas tutorial Autoregressive Integrated Moving Average atau ARIMA dengan EViews. ARIMA adalah gabungan antara model AR, MA dan differencing.

Tutorial ARIMA EViews ini akan membahas pengertian, cara dan langkah-langkah dalam melakukan analisis ARIMA yang meliputi antara lain: Uji Stasioneritas, Fitting Model terbaik beserta Uji Asumsi, Peramalan atau Forecast dan Interpretasi atau penjelasannya.
Baca juga: ARIMA dengan STATA: Pengertian, Tutorial, Cara dan Langkah!
KONSEP ARIMA
Pengertian ARIMA
Metode Autoregressive Integrated Moving Average atau ARIMA mempunyai nama lain yaitu metode Box Jenkins. Metode ini dikembangkan tahun 1970 oleh Gwilym Jenkins dan George Box. Prediksi dengan metode ARIMA akan menghasilkan suatu prediksi berdasarkan sintesis dari pola data secara historis.
Hal ini dikarenakan data yang digunakan dalam metode ARIMA adalah data history dengan menggunakan metode time series. Metode ARIMA digunakan untuk prediksi jangka pendek. Hal ini dikarenakan jika digunakan untuk prediksi jangka Panjang, ketepatan prediksinya kurang baik. Hasil prediksi yang diperoleh jika menggunakan periode jangka panjang cenderung konstan, jika menggunakan jangka pendek prediksi yang diperoleh mempunyai nilai ketepatan yang lebih akurat.

Asumsi yang digunakan dalam model ini adalah data time series yang dihasilkan bersifat stasioner. Hal ini maksudnya mean dan varian dari data bersifat konstan. Namun kenyataannya data time series banyak yang bersifat non-stasioner. Jika data yang dihasilkan mean tidak stasioner, maka dilakukan differencing dan data yang dihasilkan varian tidak stasioner dilakukan transformasi. Bentuk umum model Autoregressivve Integrated Moving Average yaitu dapat ditunjukkan pada persamaan (1).

Berdasarkan persamaan (1) diketahui bahwa merupakan data deret waktu sebagai variabel dependen waktu ke-t. Zt-p merupakan data deret waktu saat kurun waktu ke-(t-p). b1, bq, c1, cq merupakan parameter model serta et-q merupakan nilai error pada saat waktu ke-(t-q).
Prosedur ARIMA
Metode ARIMA berbeda dari metode peramalan lain karena metode ini tidak mensyaratkan suatu pola data tertentu, sehingga model dapat dipakai untuk semua tipe pola data. Metode ARIMA akan bekerja baik jika data dalam time series yang digunakan bersifat dependen atau berhubungan satu sama lain secara statistik.
Secara umum, model ARIMA ditulis dengan ARIMA (p, d, q) yang artinya model ARIMA dengan derajat AR (p), derajat pembeda yaitu d atau differencing, dan derajat MA (q).
Untuk memahami ARIMA dan langkah-langkah mengerjakan analisis ARIMA, maka kita harus memahami terlebih dahulu tentang AR, MA dan ARMA.

Autoregressive (AR)
Autoregressive (AR) adalah suatu bentuk regresi tetapi bukan yang menghubungkan variabel tak bebas, melainkan menghubungkan nilai-nlai sebelumnya pada time lag (selang waktu) yang bermacam-macam. Jadi suatu model Autoregressive akan menyatakan suatu ramalan sebagai fungsi nilai-nilai sebelumnya dari time series tertentu.
Pada umumnya, order AR yang sering digunakan dalam analisis time series adalah p = 1 atau p = 2, yaitu model AR (1) dan AR (2).
Moving Average (MA)
Moving Average atau Rata-rata Bergerak diperoleh melalui penjumlahan dan pencarian nilai rata-rata dari sejumlah periode tertentu, kemudian menghilangkan nilai terlamanya dan menambah nilai baru.
Secara umum, order MA yang sering digunakan dalam analisis time series adalah q =1 atau q = 2, yaitu MA (1) dan MA (2).
Model Autoregressive Moving Average (ARMA)
Model Autoregressive Moving Average (ARMA) merupakan suatu kombinasi dari model AR dan MA. Bentuk umum model ARMA adalah (p,q).

Model Autoregressive Integrated Moving Average (ARIMA)
Model Autoregressive Integrated Moving Average (ARIMA) merupakan gabungan dari model AR, MA dan proses differencing atau d. Sehingga bentuk umum model ARIMA adalah (p,d,q).
Tutorial ARIMA dengan EViews
Persiapan Data Untuk Analisis ARIMA dengan EViews
Sebelum memulai tutorial ARIMA dengan EViews ini, silahkan para pembaca dapat mendownload dataset excel sebagai data fiktif yang akan kita gunakan dalam tutorial ini. Silahkan download DISINI!
Dalam tutorial ini kita akan menggunakan data runtut waktu QUARTAL yaitu variabel X1. Silahkan anda buka file excel yang baru saja anda download. Selanjutnya buka aplikasi EViews anda kemudian lakukan import data tersebut dan deklarasikan sebagai data harian dimana time sebagai deret waktunya. Jika langkah anda benar, maka tampilannya akan seperti ini:

Berdasarkan data diatas, maka jumlah observasi yang digunakan dalam tutorial ini adalah sebanyak 124 observasi.
Uji Stasioneritas
Langkah pertama setelah data siap untuk dianalisis, yaitu melakukan uji stasioneritas. Dalam uji ini kita bisa menggunakan uji Akar Unit dengan metode Augmented Dickey Fueller (ADF) Test.

Silahkan klik 2 kali variabel X1 dalam aplikasi EViews anda. Setelah terbuka tampilan jendela Series, maka pada jendela tersebut anda klik tab View -> Unit Root Test. Maka akan muncul jendela Unit Root Test, kemudian pilih Test type: Augmented Dickey Fueller. Pada Test for unit root in silahkan klik Level kemudian klik OK. maka hasilnya adalah sebagai berikut:

Hasil uji stasioneritas pada data level menggunakan ADF Test diatas menunjukkan bahwa nilai Prob atau p value sebesar 0,9918 dimana lebih besar dari 0,05 maka terima H0 atau yang artinya data X1 tidak stasioner pada level. Maka selanjutnya adalah analisis stasioneritas pada data First Difference atau orde pertama.
Caranya sama dengan cara diatas, hanya saja pada Test for unit root in silahkan klik 1st difference. Hasilnya adalah sebagai berikut:

Hasil uji stasioneritas pada data first difference menggunakan ADF Test diatas menunjukkan bahwa nilai Prob atau p value sebesar 0,0000 dimana lebih kecil dari 0,05 maka terima H1 atau yang artinya data X1 stasioner pada first difference.
Jika pada analisis ini data masih belum stasioner, maka silahkan anda lanjutkan analisis stasioneritas pada data Second Difference atau orde kedua dengan cara yang sama seperti diatas, namun Test for unit root in silahkan klik 2nd difference.

Pada tahap 1 ini, kesimpulannya adalah data stasioner pada first difference, maka unsur d dalam model ARIMA(p,d,q) adalah 1. Sehingga analisis selanjutnya adalah menggunakan ARIMA (p,1,q). Langkah selanjutnya adalah menentukan nilai p dan q.
Jika seumpama data stasioner pada second difference, maka unsur d dalam ARIMA(p,d,q) adalah 2.
Menentukan nilai p dan q dalam ARIMA dengan EViews
Correlogram ARIMA dengan EViews
Cara menentukan nilai p dan q dalam ARIMA dengan EViews adalah dengan menggunakan Correlogram untuk menghasilkan diagram ACF dan PACF. Dimana ACF adalah diagram autokorelasi sedangkan PACF adalah diagram Parsial Autokorelasi. ACF ini menentukan nilai q atau MA. Sedangkan PACF menentukan nilai p atau AR.
Cara untuk mendapatkan ACF dan PACF yaitu masih pada jendela series X1 sebelumnya, silahkan klik kembali tab View -> Correlogram. Setelah muncul jendela Correlogram Specification, pada Correlogam of silahkan pilih 1st difference kemudian klik OK.
Perlu diperhatikan, anda memilih 1st difference dikarenakan hasil uji stasioneritas sebelumnya menetapkan data stasioner pada first difference atau unsur d dalam ARIMA(p,d,q) adalah 1. Jika seumpama hasil uji stasioneritas menunjukkan data stasioner pada second difference atau unsur d adalah 2, maka pada correlogram silahkan pilih 2nd difference.


Berdasarkan correlogram diatas, silahkan lihat diagram ACF atau autocorrelation, dimana tampak bahwa ACF langsung Cut-off setelah Lag ke-2, sehingga kemungkinan unsur MA atau q dalam ARIMA(p,d,q) adalah antara 0, 1 atau 2.
Kemudian lihat diagram PACF atau partial autocorrelation, menunjukkan bahwa PACF langsung Cut-off setelah Lag ke-1, sehingga kemungkinan unsur AR atau p adalah antara 0 atau 1.
Jika tampilan correlogram diatas diperbesar, akan tampai seperti berikut:

Berdasarkan gambar correlogram Eviews diatas tampak diagram ACF yang sebelah kiri, cut off baru terjadi pada lag ke-3. Dimana pada Lag-1 dan Lag-2, masih berada diluar rentang garis White Noise. Beda halnya dengan diagram PACF yang sebelah kanan, cut off terjadi pada lag ke-2, dimana pada Lag-1 masih diluar rentang garis White Noise sedangkan pada Lag-2 sudah berada di dalam rentang garis White Noise.
Identifikasi Model ARIMA dengan EViews
Identifikasi model ARIMA yang tepat dapat menggunakan panduan sebagai berikut:


Maka model ARIMA(p,d,q) yang mungkin dapat dibentuk berdasarkan hasil uji stasioneritas dan correlogram diatas adalah ARIMA(0,1,1), atau (0,1,2), (1,1,0), (1,1,1) atau (1,1,2). Jadi ada 5 kemungkinan atau opsi model yang dapat dibentuk. Selanjutnya untuk memilih 1 yang terbaik dari berbagai kemungkinan tersebut, menggunakan cara overfitting yaitu uji coba disetiap model yang mungkin tersebut.
Model yang dipilih adalah yang mempunyai nilai error terendah, adjusted r square tertinggi, memenuhi asumsi klasik dan lebih banyak variabel yang signifikan. Nilai error dapat menggunakan beberapa metode antara lain: Akaike info criterion atau AIC, Schwarz criterion atau SC dan Hannan-Quinn criterion atau HC. Namun yang paling umum digunakan adalah AIC.
Deteksi Adanya Faktor Musiman atau Seasonal
Sebelum masuk ke tahap overfitting, maka perlu dipastikan bahwa tidak ada efek atau faktor musiman. Untuk mendeteksi adanya kemungkinan faktor musiman atau seasonal, bisa menggunakan correlogram diatas. Silahkan jika diperlebar tampilannya akan tampak seperti berikut:

Anda harus cek pada setiap Lag kelipatan 12, yaitu Lag-12, 24 dan 36 atau seterusnya jika observasinya lebih banyak. Berdasarkan tampilan diatas, ternyata pada Lag 12 dan 24 menunjukkan bahwa tidak melewati White Noise, sehingga efek musiman tidak ada. Maka analisis ARIMA dengan EViews ini dapat dilanjutkan. Bagaimana jika terdapat efek musiman? Maka kita bisa melakukan analisis dengan efek musiman, yaitu analisis: Seasonal ARIMA atau disingkat SARIMA.
Overfitting
Untuk melakukan over fitting, silahkan melakukan analisis ARIMA dimulai dari opsi pertama misalnya ARIMA(0,1,1). Caranya pada menu utama EViews silahkan klik menu Quick -> Estimate Equation.

Setelah muncul jendela Equation Estimation, silahkan ketikkan perintah pada kolom Equation specification sebagai berikut: d(x1) ma(1) c. Selanjutnya klik OK.
Kode d(x1) diatas menunjukkan variabel yang diprediksi yaitu x1 pada differencing 1 atau ordo pertama. Kode c adalah menggunakan konstanta atau intercept. Sedangkan ma(1) artinya unsur q sebesar 1.
Jika correlogram pada analisis stasioneritas sebelumnya menunjukkan bahwa data stasioner pada 2nd difference atau ordo kedua atau unsur d adalah 2, maka kode d(x1) harusnya diganti menjadi d(x1,2).
Hasilnya adalah sebagai berikut:

Hasil analisis ARIMA(0,1,1) diatas adalah sebagai berikut: Nilai Prob atau p value variabel MA adalah lebih dari 0,05 artinya tidak signifikan. Nilai Adjusted R Square sebesar 0,041679. Nilai AIC sebesar 4,042634. Silahkan disimpan output tersebut atau dimasukkan ke dalam tabel, untuk nanti dibandingkan dengan opsi model yang lainnya. Selanjutnya dalam tutorial ARIMA dengan EViews ini kita akan masuk ke tahap analisis asumsi.
Asumsi Normalitas
Selanjutnya uji asumsi normalitas, autokorelasi dan heteroskedastisitas. Untuk uji normalitas, caranya pada jendela Equation yang sama pada output sebelumnya, klik tab View -> Residual Diagnostics -> Histogram – Normality Test. Kemudian jendela berikutnya klik OK.

Hasil uji normalitas Jarque Bera pada residual menunjukkan bahwa nilai probability atau nilai p value sebesar 0,869945>0,05 maka terima H0 atau yang artinya berdistribusi normal. Jika nilai p value ≤0,05 maka terima H1 atau yang berarti tidak berdistribusi normal.
Asumsi Autokorelasi
Untuk uji autokorelasi, caranya pada jendela Equation yang sama pada output sebelumnya, klik tab View -> Residual Diagnostics -> Correlogram – Q-Statistics. Kemudian jendela berikutnya klik OK.

Berdasarkan output diatas, nilai p value dimulai dan sebagian besar kurang dari 0,05 maka terima H1 yang berarti terjadi masalah autokorelasi. Maka model tidak memenuhi syarat atau asumsi non autokorelasi.
Asumsi Heteroskedastisitas
Untuk uji heteroskedastisitas, caranya pada jendela Equation yang sama pada output sebelumnya, klik tab View -> Residual Diagnostics -> Correlogram Squared Residuals. Kemudian jendela berikutnya klik OK.


Berdasarkan output diatas, nilai p value dimulai dan semuanya lebih besar dari 0,05 maka terima H0 yang berarti tidak terjadi masalah heteroskedastisitas. Maka model memenuhi syarat atau asumsi non heteroskedastisitas.
Stabilitas Model
Stabilitas model dapat dinilai berdasarkan nilai Modulus, dimana jika nilai modulus baik AR ataupun MA kurang dari 1 maka disebut stabil. Caranya adalah masih pada jendela yang sama, klik tab View -> ARMA Structure. Maka akan muncul jendela ARMA Diagnostics View. Selanjutnya pilih Diagnostics Roots dengan display Graph atau Table. Kemudian kik OK.

Berdasarkan grafik nilai Modulus diatas, ataupun jika anda menggunakan tampilan tabel, hasilnya menunjukkan bahwa nilai semua Modulus<1 atau semuanya berada dalam lingkaran sehingga disimpulkan model prediksi ARIMA ini stabil.
Silahkan output hasil uji normalitas, autokorelasi, heteroskedastisitas dan stabilitas diatas, anda simpan bersama dengan output lain sebelumnya yaitu nilai error, adjusted r square, dan banyaknya variabel yang signifikan.
Overfitting opsi model lainnya
Setelah semua hasil pada opsi model ARIMA (0,1,1) anda simpan di dalam tabel, selanjutnya lakukan analisis ARIMA opsi model berikutnya yaitu: (0,1,2), (1,1,0), (1,1,1) dan (1,1,2). Caranya adalah sama dengan langkah overfitting sebelumnya, hanya saja kode pada Equation specification anda ganti sesuai opsi model yang akan diuji. Misalnya pada ARIMA(1,1,1) adalah sebagai berikut: d(x1) ar(1) ma(1) c. Kode ar(1) artinya unsur p adalah sebesar 1, ma(1) adalah unsur q sebesar 1.
Secara lengkap kode perintah pada Equation specification pada setiap opsi model adalah sebagai berikut:
ARIMA(0,1,1) = d(x1) ma(1) c
ARIMA(0,1,2) = d(x1) ar(1) ma(1 to 2) c
ARIMA(1,1,0) = d(x1) ar(1) c
ARIMA(1,1,1) = d(x1) ar(1) ma(1) c
ARIMA(1,1,2) = d(x1) ar(1) ma(1 to 2) c
Pemilihan Model Terbaik
Setelah anda melakukan semua opsi model ARIMA seperti langkah-langkah Tutorial ARIMA dengan EViews diatas dan menyimpan semua ringkasan outputnya ke dalam tabel, maka seharusnya akan mendapatkan hasil sebagai berikut:

Berdasarkan tabel pemilihan opsi model terbaik diatas, maka berdasarkan nilai AIC, SC dan HC terendah adalah model (1,1,2). Jumlah variabel yang signifikan terbanyak dan nilai adjusted r square tertinggi juga model (1,1,2). Hasil uji asumsi juga menunjukkan bahwa model (1,1,2) yang terbaik sebab semua asumsi terpenuhi. Selain itu model (1,1,2) juga stabil. Maka dapat disimpulkan bahwa model terpilih adalah ARIMA(1,1,2).
Forecasting
Setelah model terbaik terpilih dalam tutorial ARIMA dengan EViews ini, maka langkah selanjutnya adalah melakukan forecasting atau peramalan. Dalam tutorial ARIMA dengan EViews ini, kita akan coba memprediksi atau meramalkan X1 untuk 8 kuartal kedepan.
Data X1 yang kita miliki dimulai dari Kuartal Pertama Tahun 1960 (1960Q1) sampai dengan Kuartal Keempat Tahun 1990 (1990Q4). Selanjutnya kita akan memprediksi 8 kuartal kedepan yaitu hingga Kuartal Keempat Tahun 1992 (1992Q4).
Caranya adalah anda harus berada pada jendela utama Workfile, kemudian pada menu utama EViews silahkan klik Proc -> Structure/Resize Current Page.

Selanjutnya akan muncul jendela baru yaitu jendela Workfile Structure. Silahkan anda ubah End date menjadi 1992Q4. Kemudian klik OK. Jika muncul pertanyaan resize involves …..dst, maka anda klik YES.
Selanjutnya anda harus kembali ke jendela EQUATION model terpilih anda, yaitu pada model ARIMA(1,1,2). Atau silahkan anda kembali membuat perintah ARIMA(1,1,2) dengan kode d(x1) ar(1) ma(1 to 2) c seperti langkah sebelumnya. Kemudian pada jendela tersebut, silahkan klik tab Proc -> Forecast. Silahkan Series to forecast menjadi X1, Forecast name menjadi x1f. Sedangkan lain-lain biarkan default atau apa adanya. Selanjutnya klik OK.

Maka hasil dari forecast tersebut adalah sebagai berikut:

Tampak bahwa garis biru yaitu X1 Prediksi berada diantara kedua garis merah sehingga dapat disimpulkan bahwa peramalan dari X1 mulai dari Kuartal Pertama 1991 sd Kuartal Keempat Tahun 1992 adalah stabil.

Untuk melihat data X1 prediksi pada Kuartal Pertama 1991 sd Kuartal Keempat Tahun 1992, anda bisa select series x1 dengan series baru yaitu x1f pada jendela Workfile, kemudian klik kanan, lalu klik Open -> as group. Maka tampilan prediksi tersebut seperti di bawah ini:

Prediksi X1 pada Kuartal Pertama 1991 sd Kuartal Keempat Tahun 1992 tampak seperti tabel dalam gambar diatas. Untuk menjadi catatan bahwa prediksi yang lebih jauh atau jangka panjang, diatas 20 periode kedepan kita harus lebih berhati-hati menggunakan ARIMA.
Demikianlah penjelasan kami tentang tutorial ARIMA dengan EViews. Semoga artikel ini bermanfaat. Baca juga: VECM EViews: Tutorial Analisis Time Series VECM dengan EViews dan ARDL EViews: Pengertian dan Tutorial Analisis ARDL dengan EViews.
Daftar Pustaka
Ansley, C. F., and P. Newbold. 1980. Finite sample properties of estimators for autoregressive moving average models. Journal of Econometrics 13: 159–183.
Box, G. E. P., G. M. Jenkins, and G. C. Reinsel. 2008. Time Series Analysis: Forecasting and Control. 4th ed. Hoboken, NJ: Wiley.
Chatfield, C. 2004. The Analysis of Time Series: An Introduction. 6th ed. Boca Raton, FL: Chapman & Hall/CRC.
Enders, W. 2004. Applied Econometric Time Series. 2nd ed. New York: Wiley.
Greene, W. H. 2012. Econometric Analysis. 7th ed. Upper Saddle River, NJ: Prentice Hall.
Hamilton, J. D. 1994. Time Series Analysis. Princeton: Princeton University Press.
Harvey, A. C. 1989. Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge: Cambridge University Press.
Holan, S. H., R. Lund, and G. Davis. 2010. The ARMA alphabet soup: A tour of ARMA model variants. Statistics Surveys 4: 232–274.


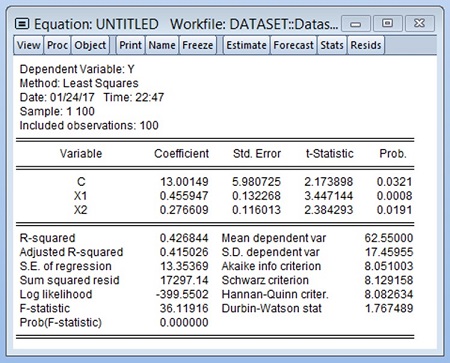

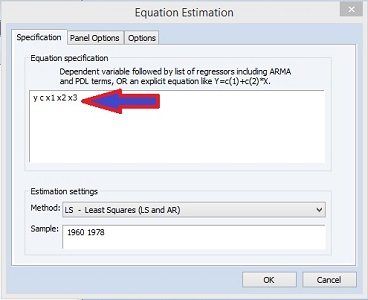

Hello STATISTIKIAN, saya mau bertanya untuk uji data mra dengan kasus
1 y, 1 z dan 23 x kenapa tidak bisa dilakukan di eviews. saya bertanya setelah membaca seluruh tutorial yang ada pada website anda. terima kasih
MRA itu artinya Regresi dengan variabel Moderasi. Dengan adanya variabel moderasi maka akan ada variabel yang merupakan hasil perkalian operasi matematis antar variabel sehingga tidak dapat dihindari adanya korelasi kuat antar variabel yang merupakan hasil perkalian dengan unsur pengalinya, misalnya antara X1 dengan X1*Z atau Z dengan X1*Z. Adanya korelasi kuat antar variabel bebas maka otomatis akan menyebabkan multikolinearitas sehingga akan melanggar asumsi. Ditambah lagi jika terlalu banyak variabel bebas maka potensi akan terjadinya multikolinearitas makin besar sebab resiko korelasi kuat antar variabel bebas akan makin tinggi, apalagi jika sampai terjadi korelasi sempurna atau mendekati sempurna akan menyebabkan kegagalan perhitungan matrix varians covarians dalam regresi yang pada akhirnya analisis regresi itu sendiri tidak dapat dilakukan.
Terima kasih banyak Pak